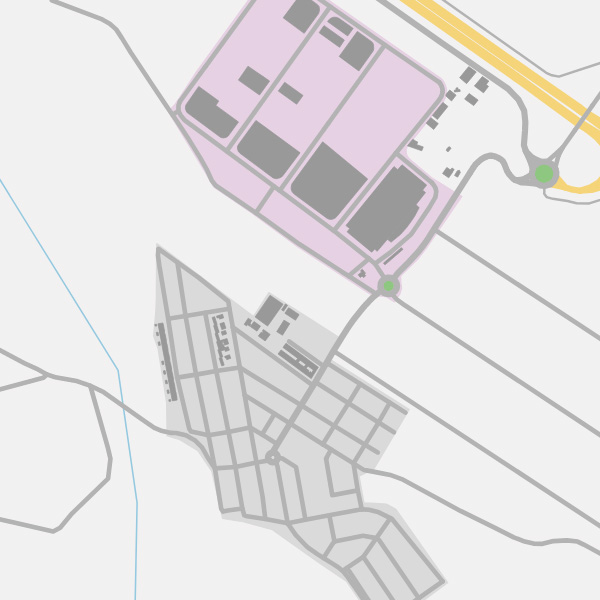
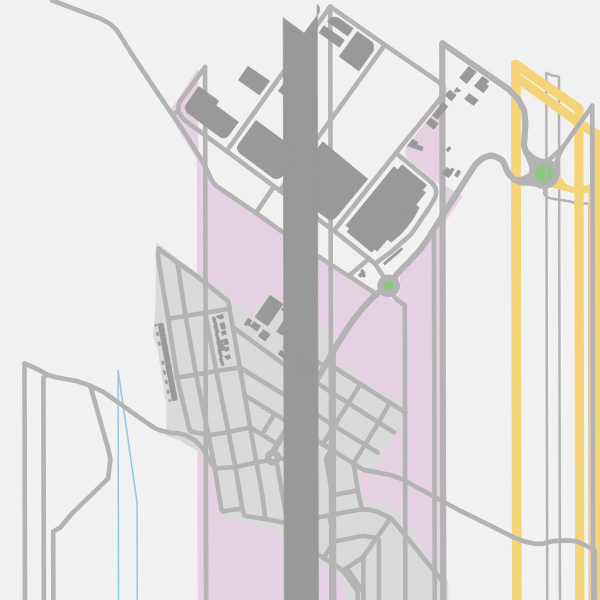
I'm trying to download xml data giving a coordenates from my page calling to "https://overpass-api.de/api/map?bbox=-0.678492,39.657480,-0.665617,39.667391". After this I get the map.osm file. The problem begins when I call to the page mentioned above several times in a few time (maybe 10 times in 8-10 minutes). When I do this, I get (not always) a "failed to open stream: HTTP request failed! HTTP/1.1 429 Too Many Requests" error in my php script. This is the map I get when it works: So, as a second option I tried to call to "https://lz4.overpass-api.de/api/interpreter?data=[bbox];(node;way;relation;);out%20bb;&bbox=-0.678492,39.657480,-0.665617,39.667391" in order to avoid the error on the previous URL. The problem doing this is that the downloaded map.osm file seems to miss some nodes, so they can't be found when drawing map. This is the map I get from this URL:
asked 02 May '19, 13:04 r3287 |
One Answer:
No, this is not a problem in OSM. You ask the server to retrieve ways and relations without the node referenced there. The server faithfully sends back that data to you. The script is most likely turning missing nodes into the coordinate (0,0) which explains the line segments leaving the image to the bottom. I would like to encourage you to make you familiar with the OpenStreetMap data model first. answered 03 May '19, 21:47 Roland Olbricht Thanks for your response. First of all, I think I'm familiar with OSM data, as I'm doing this script since some months ago. I don't know what do you mean with "the node referenced there". I thought passing bounding box was enough to get an area. Secondly, it seems like the second URL returns all nodes except those that are outside the bounding area, that's the reason why my script doesn't know where it has to continue drawing more lines (because the .osm file makes reference to a node ID, but when tries to find that node, it does not exist) and goes to the bottom of the image. It doesn't make much sense that asking for the same bounding area, it receives different nodes from both URLs. Do you think I'm missing something when asking to the server? (04 May '19, 12:19) r3287 |
I kindly invite you to read the error message, in particular the words Too many requests.